MLFlow¶
We show how LaminDB can be integrated with MLflow to track the training process and associate datasets & parameters with models.
# !pip install 'lamindb[jupyter]' torchvision lightning wandb
!lamin init --storage ./lamin-mlops
import lamindb as ln
import mlflow
import lightning
from torch import utils
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
from autoencoder import LitAutoEncoder
ln.track()
Show code cell output
→ connected lamindb: anonymous/lamin-mlops
→ created Transform('4DNL2117IUOw0000'), started new Run('Z4bpNBFi...') at 2025-06-10 20:15:40 UTC
→ notebook imports: autoencoder lamindb==1.6.1 lightning==2.5.1.post0 mlflow-skinny==3.0.0 mlflow==3.0.0 torch==2.7.1 torchvision==0.22.1
• recommendation: to identify the notebook across renames, pass the uid: ln.track("4DNL2117IUOw")
Define a model¶
We use a basic PyTorch Lightning autoencoder as an example model.
Code of LitAutoEncoder
Simple autoencoder model¶
import torch
import lightning
from torch import optim, nn
class LitAutoEncoder(lightning.LightningModule):
def __init__(self, hidden_size: int, bottleneck_size: int) -> None:
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(28 * 28, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, bottleneck_size),
)
self.decoder = nn.Sequential(
nn.Linear(bottleneck_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, 28 * 28),
)
self.save_hyperparameters()
def training_step(
self, batch: tuple[torch.Tensor, torch.Tensor], batch_idx: int
) -> torch.Tensor:
x, y = batch
x = x.view(x.size(0), -1)
z = self.encoder(x)
x_hat = self.decoder(z)
loss = nn.functional.mse_loss(x_hat, x)
self.log("train_loss", loss)
return loss
def configure_optimizers(self) -> optim.Optimizer:
optimizer = optim.Adam(self.parameters(), lr=1e-3)
return optimizer
Query & download the MNIST dataset¶
We saved the MNIST dataset in curation notebook which now shows up in the Artifact registry:
ln.Artifact.filter(kind="dataset").df()
Show code cell output
| uid | key | description | suffix | kind | otype | size | hash | n_files | n_observations | _hash_type | _key_is_virtual | _overwrite_versions | space_id | storage_id | schema_id | version | is_latest | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||||
| 1 | rORgljIU66Y5otvE0000 | testdata/mnist | None | dataset | None | 54950048 | amFx_vXqnUtJr0kmxxWK2Q | 4 | None | md5-d | True | True | 1 | 1 | None | None | True | 1 | 2025-06-10 20:15:07.304000+00:00 | 1 | None | 1 |
You can also find it on lamin.ai if you were connected your instance.
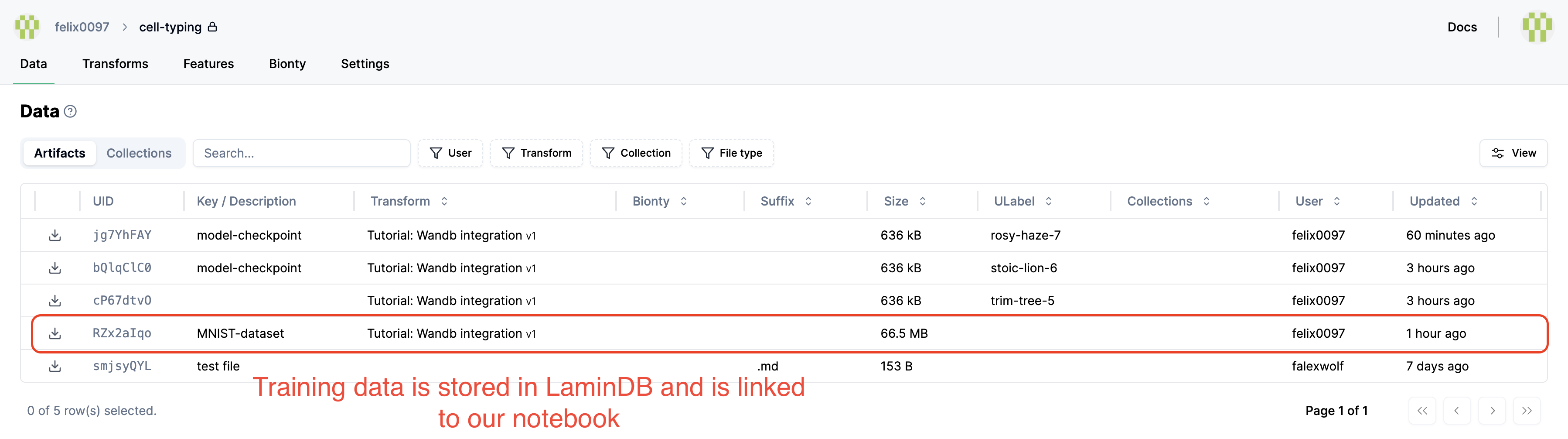
Let’s get the dataset:
artifact = ln.Artifact.get(key="testdata/mnist")
artifact
Show code cell output
Artifact(uid='rORgljIU66Y5otvE0000', is_latest=True, key='testdata/mnist', suffix='', kind='dataset', size=54950048, hash='amFx_vXqnUtJr0kmxxWK2Q', n_files=4, branch_id=1, space_id=1, storage_id=1, run_id=1, created_by_id=1, created_at=2025-06-10 20:15:07 UTC)
And download it to a local cache:
path = artifact.cache()
path
Show code cell output
PosixUPath('/home/runner/work/lamin-mlops/lamin-mlops/docs/lamin-mlops/.lamindb/rORgljIU66Y5otvE')
Create a PyTorch-compatible dataset:
dataset = MNIST(path.as_posix(), transform=ToTensor())
dataset
Show code cell output
Dataset MNIST
Number of datapoints: 60000
Root location: /home/runner/work/lamin-mlops/lamin-mlops/docs/lamin-mlops/.lamindb/rORgljIU66Y5otvE
Split: Train
StandardTransform
Transform: ToTensor()
Monitor training with MLflow¶
Train our example model and track the training progress with MLflow.
mlflow.pytorch.autolog()
MODEL_CONFIG = {"hidden_size": 32, "bottleneck_size": 16, "batch_size": 32}
# Start MLflow run
with mlflow.start_run() as run:
train_dataset = MNIST(
root="./data", train=True, download=True, transform=ToTensor()
)
train_loader = utils.data.DataLoader(
train_dataset, batch_size=MODEL_CONFIG["batch_size"]
)
# Initialize model
autoencoder = LitAutoEncoder(
MODEL_CONFIG["hidden_size"], MODEL_CONFIG["bottleneck_size"]
)
# Create checkpoint callback
from lightning.pytorch.callbacks import ModelCheckpoint
checkpoint_callback = ModelCheckpoint(
dirpath="model_checkpoints",
filename=f"{run.info.run_id}_last_epoch",
save_top_k=1,
monitor="train_loss",
)
# Train model
trainer = lightning.Trainer(
accelerator="cpu",
limit_train_batches=3,
max_epochs=2,
callbacks=[checkpoint_callback],
)
trainer.fit(model=autoencoder, train_dataloaders=train_loader)
# Get run information
run_id = run.info.run_id
metrics = mlflow.get_run(run_id).data.metrics
params = mlflow.get_run(run_id).data.params
# Access model artifacts path
model_uri = f"runs:/{run_id}/model"
artifacts_path = run.info.artifact_uri
Show code cell output
2025/06/10 20:15:41 WARNING mlflow.utils.autologging_utils: MLflow pytorch autologging is known to be compatible with 2.1.0 <= torch <= 2.7.0, but the installed version is 2.7.1+cu126. If you encounter errors during autologging, try upgrading / downgrading torch to a compatible version, or try upgrading MLflow.
0%| | 0.00/9.91M [00:00<?, ?B/s]
1%| | 98.3k/9.91M [00:00<00:11, 866kB/s]
4%|▍ | 393k/9.91M [00:00<00:05, 1.86MB/s]
16%|█▌ | 1.54M/9.91M [00:00<00:01, 5.36MB/s]
34%|███▍ | 3.41M/9.91M [00:00<00:00, 9.52MB/s]
55%|█████▍ | 5.44M/9.91M [00:00<00:00, 12.4MB/s]
78%|███████▊ | 7.70M/9.91M [00:00<00:00, 14.8MB/s]
100%|██████████| 9.91M/9.91M [00:00<00:00, 13.0MB/s]
0%| | 0.00/28.9k [00:00<?, ?B/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 510kB/s]
0%| | 0.00/1.65M [00:00<?, ?B/s]
4%|▍ | 65.5k/1.65M [00:00<00:02, 579kB/s]
20%|█▉ | 328k/1.65M [00:00<00:00, 1.59MB/s]
79%|███████▉ | 1.31M/1.65M [00:00<00:00, 4.79MB/s]
100%|██████████| 1.65M/1.65M [00:00<00:00, 4.78MB/s]
0%| | 0.00/4.54k [00:00<?, ?B/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 8.59MB/s]
INFO:pytorch_lightning.utilities.rank_zero:GPU available: False, used: False
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
/opt/hostedtoolcache/Python/3.13.3/x64/lib/python3.13/site-packages/lightning/pytorch/trainer/connectors/logger_connector/logger_connector.py:76: Starting from v1.9.0, `tensorboardX` has been removed as a dependency of the `lightning.pytorch` package, due to potential conflicts with other packages in the ML ecosystem. For this reason, `logger=True` will use `CSVLogger` as the default logger, unless the `tensorboard` or `tensorboardX` packages are found. Please `pip install lightning[extra]` or one of them to enable TensorBoard support by default
/opt/hostedtoolcache/Python/3.13.3/x64/lib/python3.13/site-packages/lightning/pytorch/callbacks/model_checkpoint.py:654: Checkpoint directory /home/runner/work/lamin-mlops/lamin-mlops/docs/model_checkpoints exists and is not empty.
| Name | Type | Params | Mode
-----------------------------------------------
0 | encoder | Sequential | 25.6 K | train
1 | decoder | Sequential | 26.4 K | train
-----------------------------------------------
52.1 K Trainable params
0 Non-trainable params
52.1 K Total params
0.208 Total estimated model params size (MB)
8 Modules in train mode
0 Modules in eval mode
/opt/hostedtoolcache/Python/3.13.3/x64/lib/python3.13/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:425: The 'train_dataloader' does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` to `num_workers=3` in the `DataLoader` to improve performance.
/opt/hostedtoolcache/Python/3.13.3/x64/lib/python3.13/site-packages/lightning/pytorch/loops/fit_loop.py:310: The number of training batches (3) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
Training: | | 0/? [00:00<?, ?it/s]
Training: 0%| | 0/3 [00:00<?, ?it/s]
Epoch 0: 0%| | 0/3 [00:00<?, ?it/s]
Epoch 0: 33%|███▎ | 1/3 [00:00<00:00, 49.03it/s]
Epoch 0: 33%|███▎ | 1/3 [00:00<00:00, 47.25it/s, v_num=0]
Epoch 0: 67%|██████▋ | 2/3 [00:00<00:00, 68.11it/s, v_num=0]
Epoch 0: 67%|██████▋ | 2/3 [00:00<00:00, 66.86it/s, v_num=0]
Epoch 0: 100%|██████████| 3/3 [00:00<00:00, 81.76it/s, v_num=0]
Epoch 0: 100%|██████████| 3/3 [00:00<00:00, 80.11it/s, v_num=0]
Epoch 0: 100%|██████████| 3/3 [00:00<00:00, 78.78it/s, v_num=0]
2025/06/10 20:15:44 WARNING mlflow.utils.checkpoint_utils: Checkpoint logging is skipped, because checkpoint 'save_best_only' config is True, it requires to compare the monitored metric value, but the provided monitored metric value is not available.
Epoch 0: 0%| | 0/3 [00:00<?, ?it/s, v_num=0]
Epoch 1: 0%| | 0/3 [00:00<?, ?it/s, v_num=0]
Epoch 1: 33%|███▎ | 1/3 [00:00<00:00, 139.96it/s, v_num=0]
Epoch 1: 33%|███▎ | 1/3 [00:00<00:00, 129.19it/s, v_num=0]
Epoch 1: 67%|██████▋ | 2/3 [00:00<00:00, 141.36it/s, v_num=0]
Epoch 1: 67%|██████▋ | 2/3 [00:00<00:00, 134.66it/s, v_num=0]
Epoch 1: 100%|██████████| 3/3 [00:00<00:00, 142.66it/s, v_num=0]
Epoch 1: 100%|██████████| 3/3 [00:00<00:00, 139.52it/s, v_num=0]
Epoch 1: 100%|██████████| 3/3 [00:00<00:00, 135.05it/s, v_num=0]
2025/06/10 20:15:44 WARNING mlflow.utils.checkpoint_utils: Checkpoint logging is skipped, because checkpoint 'save_best_only' config is True, it requires to compare the monitored metric value, but the provided monitored metric value is not available.
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=2` reached.
Epoch 1: 100%|██████████| 3/3 [00:00<00:00, 103.97it/s, v_num=0]
2025/06/10 20:15:50 WARNING mlflow.models.model: Model logged without a signature and input example. Please set `input_example` parameter when logging the model to auto infer the model signature.
See the training progress in the mlflow UI:
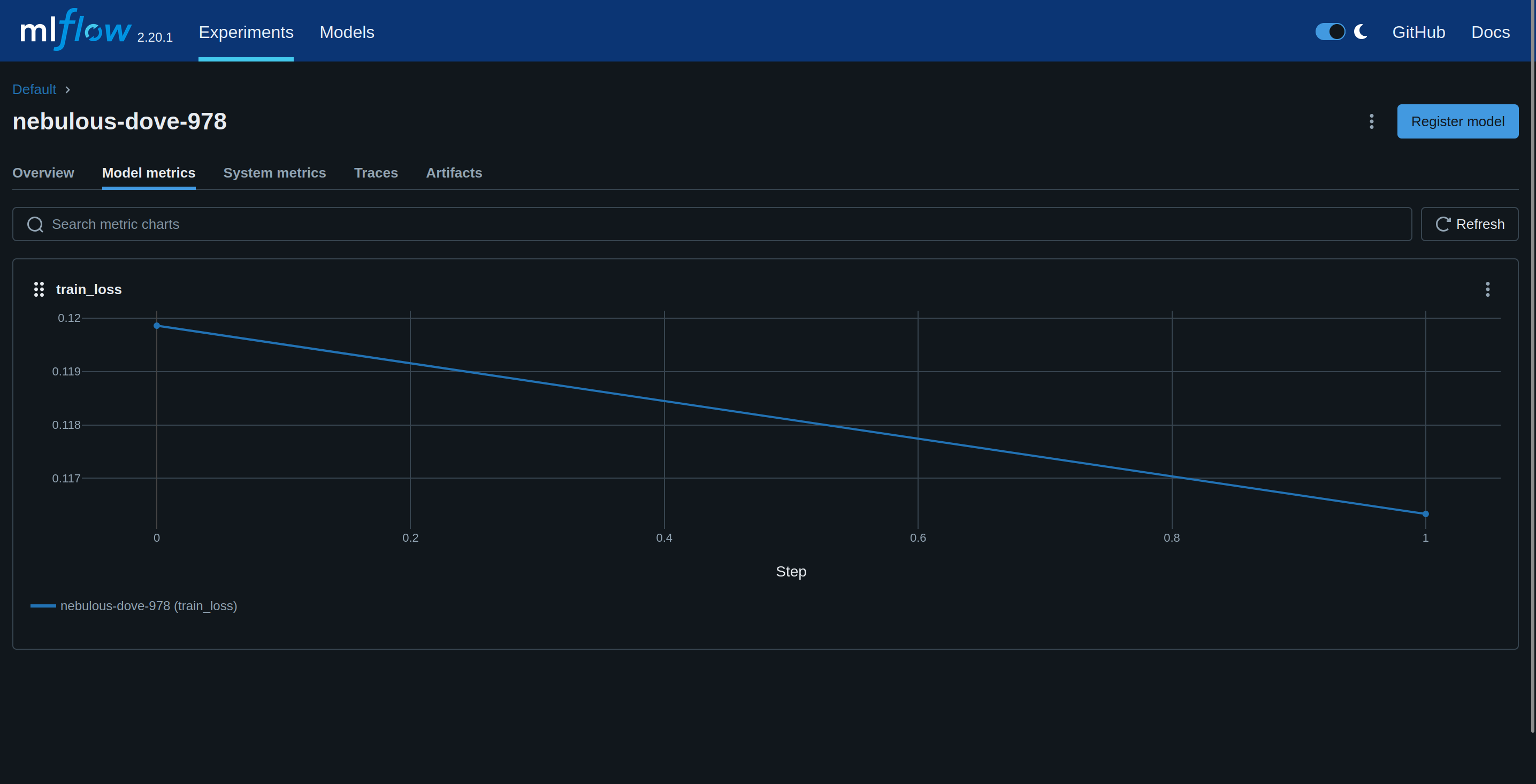
Save model in LaminDB¶
# save checkpoint as a model in LaminDB
artifact = ln.Artifact(
f"model_checkpoints/{run_id}_last_epoch.ckpt",
key="testmodels/mlflow/litautoencoder.ckpt", # is automatically versioned
type="model",
).save()
# create a label with the mlflow experiment name
mlflow_run_name = mlflow.get_run(run_id).data.tags.get(
"mlflow.runName", f"run_{run_id}"
)
experiment_label = ln.ULabel(
name=mlflow_run_name, description="mlflow experiment name"
).save()
# annotate the model Artifact
artifact.ulabels.add(experiment_label)
# define the associated model hyperparameters in ln.Param
for k, v in MODEL_CONFIG.items():
ln.Param(name=k, dtype=type(v).__name__).save()
artifact.params.add_values(MODEL_CONFIG)
# look at Artifact annotations
artifact.describe()
artifact.params
Show code cell output
! `type` will be removed soon, please use `kind`
! calling anonymously, will miss private instances
→ returning existing Feature record with same name: 'hidden_size'
→ returning existing Feature record with same name: 'bottleneck_size'
→ returning existing Feature record with same name: 'batch_size'
/tmp/ipykernel_3833/2236147127.py:22: FutureWarning: Use features instead of params, params will be removed in the future.
artifact.params.add_values(MODEL_CONFIG)
Artifact .ckpt ├── General │ ├── .uid = 'E2BUcNlYXpk96lu10000' │ ├── .key = 'testmodels/mlflow/litautoencoder.ckpt' │ ├── .size = 636736 │ ├── .hash = 'lzxQH5RaNEr6FCg3j61G6Q' │ ├── .path = /home/runner/work/lamin-mlops/lamin-mlops/docs/lamin-mlops/.lamindb/E2BUcNlYXpk96lu10000.ckpt │ ├── .created_by = anonymous │ ├── .created_at = 2025-06-10 20:15:51 │ └── .transform = 'MLFlow' ├── Linked features │ └── batch_size int 32 │ bottleneck_size int 16 │ hidden_size int 32 └── Labels └── .ulabels ULabel grandiose-shoat-501
/tmp/ipykernel_3833/2236147127.py:26: FutureWarning: Use features instead of params, params will be removed in the future.
artifact.params
Artifact .ckpt └── Linked features └── batch_size int 32 bottleneck_size int 16 hidden_size int 32
See the checkpoints:
If later on, you want to re-use the checkpoint, you can download it like so:
ln.Artifact.get(key="testmodels/mlflow/litautoencoder.ckpt").cache()
Show code cell output
PosixUPath('/home/runner/work/lamin-mlops/lamin-mlops/docs/lamin-mlops/.lamindb/E2BUcNlYXpk96lu10000.ckpt')
Or on the CLI:
lamin get artifact --key 'testmodels/litautoencoder'
ln.finish()
Show code cell output
! cells [(9, 11)] were not run consecutively
→ finished Run('Z4bpNBFi') after 11s at 2025-06-10 20:15:52 UTC
Show code cell content
!rm -rf ./lamin-mlops
!lamin delete --force lamin-mlops
! calling anonymously, will miss private instances
• deleting instance anonymous/lamin-mlops